publications
2024
-
 Population-level coding of avoidance learning in medial prefrontal cortexBenjamin Ehret, Roman Boehringer, Elizabeth A Amadei, and 5 more authorsNature Neuroscience. See this repo on information on how to build and control the experimental setup , 2024
Population-level coding of avoidance learning in medial prefrontal cortexBenjamin Ehret, Roman Boehringer, Elizabeth A Amadei, and 5 more authorsNature Neuroscience. See this repo on information on how to build and control the experimental setup , 2024The medial prefrontal cortex (mPFC) has been proposed to link sensory inputs and behavioral outputs to mediate the execution of learned behaviors. However, how such a link is implemented has remained unclear. To measure prefrontal neural correlates of sensory stimuli and learned behaviors, we performed population calcium imaging during a new tone-signaled active avoidance paradigm in mice. We developed an analysis approach based on dimensionality reduction and decoding that allowed us to identify interpretable task-related population activity patterns. While a large fraction of tone-evoked activity was not informative about behavior execution, we identified an activity pattern that was predictive of tone-induced avoidance actions and did not occur for spontaneous actions with similar motion kinematics. Moreover, this avoidance-specific activity differed between distinct avoidance actions learned in two consecutive tasks. Overall, our results are consistent with a model in which mPFC contributes to the selection of goal-directed actions by transforming sensory inputs into specific behavioral outputs through distributed population-level computations.
@article{ehret2024population, title = {Population-level coding of avoidance learning in medial prefrontal cortex}, author = {Ehret, Benjamin and Boehringer, Roman and Amadei, Elizabeth A and Cervera, Maria R and Henning, Christian and Galgali, Aniruddh R and Mante, Valerio and Grewe, Benjamin F}, journal = {Nature Neuroscience}, volume = {27}, number = {9}, pages = {1805--1815}, year = {2024}, publisher = {Nature Publishing Group US New York}, doi = {10.1038/s41593-024-01704-5}, }
2022
-
 Knowledge uncertainty and lifelong learning in neural systemsChristian HenningPhD Thesis , 2022
Knowledge uncertainty and lifelong learning in neural systemsChristian HenningPhD Thesis , 2022Natural intelligence has the ability to continuously learn from its environment, an environment that is constantly changing and thus induces uncertainties that need to be coped with to ensure survival. By contrast, artificial intelligence (AI) commonly learns from data only once during a particular training phase, and rarely explicitly represents or utilizes uncertainties. In this thesis, we contribute towards improving AI in these regards by designing and understanding neural network-based models that learn continually and that explicitly represent several sources of uncertainty, with the ultimate goal of obtaining models that are useful, reliable and practical. We start by setting this research into a broader context and providing an introduction to the fields of uncertainty estimation and continual learning. This detailed review can constitute an entry point for those interested in familiarizing themselves with these topics. After laying this foundation, we dive into the specific question of how to learn a set of tasks continually and present our approach for solving this problem based on a system of neural networks. More specifically, we train a meta-network to generate task-specific parameters for an inference model and show that, in this setting, forgetting can be prevented using a simple regularization at the meta-level. Due to the existence of task-specific solutions, the problem arises of having to infer the task to which an unseen input belongs. We investigate two major ways for solving this \emphtask-inference problem: (i) replay-based and (ii) uncertainty-based. While replay-based task-inference exhibits remarkable performance on simple benchmarks, our implementation of this method relies on generative modelling, which becomes disproportionately difficult with increased task complexity. Uncertainty-based task-inference, on the other hand, does not rely on external models and scales more easily to complex scenarios. Because calibrating the uncertainties required for task-inference is difficult, in practice, one often resorts to models that should \emphknow what they don’t know. This can in theory be achieved through a Bayesian treatment of model parameters. However, due to the difficulty in interpreting the prior knowledge given to a neural network-based model, it also becomes difficult to interpret what it is that the model \emphknows not to know. This realization has implications beyond continual learning, and more generally affects how current machine learning models handle unseen inputs. We discuss the intricacies associated with choosing prior knowledge in neural networks and show that common choices often lead to uncertainties that do not intrinsically reflect certain desiderata such as detecting unseen inputs that the model should not generalize to. Overall, this thesis compactly summarizes and contributes to the advancement of two important topics in nowadays deep learning research, uncertainty estimation and continual learning, while disclosing existing challenges, evaluating novel approaches and identifying promising avenues for future research.
@article{henning2022phdthesis, title = {Knowledge uncertainty and lifelong learning in neural systems}, author = {Henning, Christian}, year = {2022}, publisher = {ETH Zurich}, }
2021
- Continual Learning in Recurrent Neural NetworksBenjamin Ehret*, Christian Henning*, Maria R. Cervera*, and 3 more authorsIn International Conference on Learning Representations, 2021
While a diverse collection of continual learning (CL) methods has been proposed to prevent catastrophic forgetting, a thorough investigation of their effectiveness for processing sequential data with recurrent neural networks (RNNs) is lacking. Here, we provide the first comprehensive evaluation of established CL methods on a variety of sequential data benchmarks. Specifically, we shed light on the particularities that arise when applying weight-importance methods, such as elastic weight consolidation, to RNNs. In contrast to feedforward networks, RNNs iteratively reuse a shared set of weights and require working memory to process input samples. We show that the performance of weight-importance methods is not directly affected by the length of the processed sequences, but rather by high working memory requirements, which lead to an increased need for stability at the cost of decreased plasticity for learning subsequent tasks. We additionally provide theoretical arguments supporting this interpretation by studying linear RNNs. Our study shows that established CL methods can be successfully ported to the recurrent case, and that a recent regularization approach based on hypernetworks outperforms weight-importance methods, thus emerging as a promising candidate for CL in RNNs. Overall, we provide insights on the differences between CL in feedforward networks and RNNs, while guiding towards effective solutions to tackle CL on sequential data.
@inproceedings{ehret2020recurrenthypercl, title = {Continual Learning in Recurrent Neural Networks}, author = {Ehret, Benjamin and Henning, Christian and Cervera, Maria R. and Meulemans, Alexander and von Oswald, Johannes and Grewe, Benjamin F.}, booktitle = {International Conference on Learning Representations}, year = {2021}, } - Neural networks with late-phase weightsJohannes Von Oswald*, Seijin Kobayashi*, Joao Sacramento, and 3 more authorsIn International Conference on Learning Representations, 2021
The largely successful method of training neural networks is to learn their weights using some variant of stochastic gradient descent (SGD). Here, we show that the solutions found by SGD can be further improved by ensembling a subset of the weights in late stages of learning. At the end of learning, we obtain back a single model by taking a spatial average in weight space. To avoid incurring increased computational costs, we investigate a family of low-dimensional late-phase weight models which interact multiplicatively with the remaining parameters. Our results show that augmenting standard models with late-phase weights improves generalization in established benchmarks such as CIFAR-10/100, ImageNet and enwik8. These findings are complemented with a theoretical analysis of a noisy quadratic problem which provides a simplified picture of the late phases of neural network learning.
@inproceedings{oswald2021late:phase:weights, title = {Neural networks with late-phase weights}, author = {Oswald, Johannes Von and Kobayashi, Seijin and Sacramento, Joao and Meulemans, Alexander and Henning, Christian and Grewe, Benjamin F}, booktitle = {International Conference on Learning Representations}, year = {2021}, } - Posterior Meta-Replay for Continual LearningChristian Henning*, Maria R. Cervera*, Francesco D’Angelo, and 6 more authorsIn Conference on Neural Information Processing Systems, 2021
Learning a sequence of tasks without access to i.i.d. observations is a widely studied form of continual learning (CL) that remains challenging. In principle, Bayesian learning directly applies to this setting, since recursive and one-off Bayesian updates yield the same result. In practice, however, recursive updating often leads to poor trade-off solutions across tasks because approximate inference is necessary for most models of interest. Here, we describe an alternative Bayesian approach where task-conditioned parameter distributions are continually inferred from data. We offer a practical deep learning implementation of our framework based on probabilistic task-conditioned hypernetworks, an approach we term posterior meta-replay. Experiments on standard benchmarks show that our probabilistic hypernetworks compress sequences of posterior parameter distributions with virtually no forgetting. We obtain considerable performance gains compared to existing Bayesian CL methods, and identify task inference as our major limiting factor. This limitation has several causes that are independent of the considered sequential setting, opening up new avenues for progress in CL.
@inproceedings{posterior:replay:2021:henning:cervera, title = {Posterior Meta-Replay for Continual Learning}, author = {Henning, Christian and Cervera, Maria R. and D'Angelo, Francesco and von Oswald, Johannes and Traber, Regina and Ehret, Benjamin and Kobayashi, Seijin and Grewe, Benjamin F. and Sacramento, João}, booktitle = {Conference on Neural Information Processing Systems}, year = {2021}, } - Are Bayesian neural networks intrinsically good at out-of-distribution detection?Christian Henning*, Francesco D’Angelo*, and Benjamin F. GreweIn ICML Workshop on Uncertainty and Robustness in Deep Learning. (Spotlight) , 2021
The need to avoid confident predictions on unfamiliar data has sparked interest in out-of-distribution (OOD) detection. It is widely assumed that Bayesian neural networks (BNN) are well suited for this task, as the endowed epistemic uncertainty should lead to disagreement in predictions on outliers. In this paper, we question this assumption and provide empirical evidence that proper Bayesian inference with common neural network architectures does not necessarily lead to good OOD detection. To circumvent the use of approximate inference, we start by studying the infinite-width case, where Bayesian inference can be exact considering the corresponding Gaussian process. Strikingly, the kernels induced under common architectural choices lead to uncertainties that do not reflect the underlying data generating process and are therefore unsuited for OOD detection. Finally, we study finite-width networks using HMC, and observe OOD behavior that is consistent with the infinite-width case. Overall, our study discloses fundamental problems when naively using BNNs for OOD detection and opens interesting avenues for future research.
@inproceedings{henning:dangelo:2021:bayesian:ood, title = {Are Bayesian neural networks intrinsically good at out-of-distribution detection?}, author = {Henning, Christian and D'Angelo, Francesco and Grewe, Benjamin F.}, booktitle = {ICML Workshop on Uncertainty and Robustness in Deep Learning}, year = {2021}, } - Uncertainty estimation under model misspecification in neural network regressionMaria R. Cervera*, Rafael Dätwyler*, Francesco D’Angelo*, and 3 more authorsIn NeurIPS Workshop on Robustness and misspecification in probabilistic modeling. (Spotlight) , 2021
Although neural networks are powerful function approximators, the underlying modelling assumptions ultimately define the likelihood and thus the hypothesis class they are parameterizing. In classification, these assumptions are minimal as the commonly employed softmax is capable of representing any categorical distribution. In regression, however, restrictive assumptions on the type of continuous distribution to be realized are typically placed, like the dominant choice of training via mean-squared error and its underlying Gaussianity assumption. Recently, modelling advances allow to be agnostic to the type of continuous distribution to be modelled, granting regression the flexibility of classification models. While past studies stress the benefit of such flexible regression models in terms of performance, here we study the effect of the model choice on uncertainty estimation. We highlight that under model misspecification, aleatoric uncertainty is not properly captured, and that a Bayesian treatment of a misspecified model leads to unreliable epistemic uncertainty estimates. Overall, our study provides an overview on how modelling choices in regression may influence uncertainty estimation and thus any downstream decision making process.
@inproceedings{cervera:henning:2021:regression, title = {Uncertainty estimation under model misspecification in neural network regression}, author = {Cervera, Maria R. and Dätwyler, Rafael and D'Angelo, Francesco and Keurti, Hamza and Grewe, Benjamin F. and Henning, Christian}, booktitle = {NeurIPS Workshop on Robustness and misspecification in probabilistic modeling}, year = {2021}, } -
 On out-of-distribution detection with Bayesian neural networksFrancesco D’Angelo* and Christian Henning*See also our shorter workshop paper , 2021
On out-of-distribution detection with Bayesian neural networksFrancesco D’Angelo* and Christian Henning*See also our shorter workshop paper , 2021The question whether inputs are valid for the problem a neural network is trying to solve has sparked interest in out-of-distribution (OOD) detection. It is widely assumed that Bayesian neural networks (BNNs) are well suited for this task, as the endowed epistemic uncertainty should lead to disagreement in predictions on outliers. In this paper, we question this assumption and show that proper Bayesian inference with function space priors induced by neural networks does not necessarily lead to good OOD detection. To circumvent the use of approximate inference, we start by studying the infinite-width case, where Bayesian inference can be exact due to the correspondence with Gaussian processes. Strikingly, the kernels derived from common architectural choices lead to function space priors which induce predictive uncertainties that do not reflect the underlying input data distribution and are therefore unsuited for OOD detection. Importantly, we find the OOD behavior in this limiting case to be consistent with the corresponding finite-width case. To overcome this limitation, useful function space properties can also be encoded in the prior in weight space, however, this can currently only be applied to a specified subset of the domain and thus does not inherently extend to OOD data. Finally, we argue that a trade-off between generalization and OOD capabilities might render the application of BNNs for OOD detection undesirable in practice. Overall, our study discloses fundamental problems when naively using BNNs for OOD detection and opens interesting avenues for future research.
@online{dangelo:henning:2021:uncertainty:based:ood, title = {On out-of-distribution detection with Bayesian neural networks}, author = {D'Angelo, Francesco and Henning, Christian}, year = {2021}, eprinttype = {arXiv}, dimensions = {true}, }
2020
- Continual learning with hypernetworksJohannes Oswald*, Christian Henning*, Benjamin F. Grewe, and 1 more authorIn International Conference on Learning Representations. (Spotlight) , 2020
Artificial neural networks suffer from catastrophic forgetting when they are sequentially trained on multiple tasks. To overcome this problem, we present a novel approach based on task-conditioned hypernetworks, i.e., networks that generate the weights of a target model based on task identity. Continual learning (CL) is less difficult for this class of models thanks to a simple key feature: instead of recalling the input-output relations of all previously seen data, task-conditioned hypernetworks only require rehearsing task-specific weight realizations, which can be maintained in memory using a simple regularizer. Besides achieving state-of-the-art performance on standard CL benchmarks, additional experiments on long task sequences reveal that task-conditioned hypernetworks display a very large capacity to retain previous memories. Notably, such long memory lifetimes are achieved in a compressive regime, when the number of trainable hypernetwork weights is comparable or smaller than target network size. We provide insight into the structure of low-dimensional task embedding spaces (the input space of the hypernetwork) and show that task-conditioned hypernetworks demonstrate transfer learning. Finally, forward information transfer is further supported by empirical results on a challenging CL benchmark based on the CIFAR-10/100 image datasets.
@inproceedings{oshg2019hypercl, title = {Continual learning with hypernetworks}, author = {von Oswald, Johannes and Henning, Christian and Grewe, Benjamin F. and Sacramento, Jo{\~a}o}, booktitle = {International Conference on Learning Representations}, year = {2020}, }
2018
-
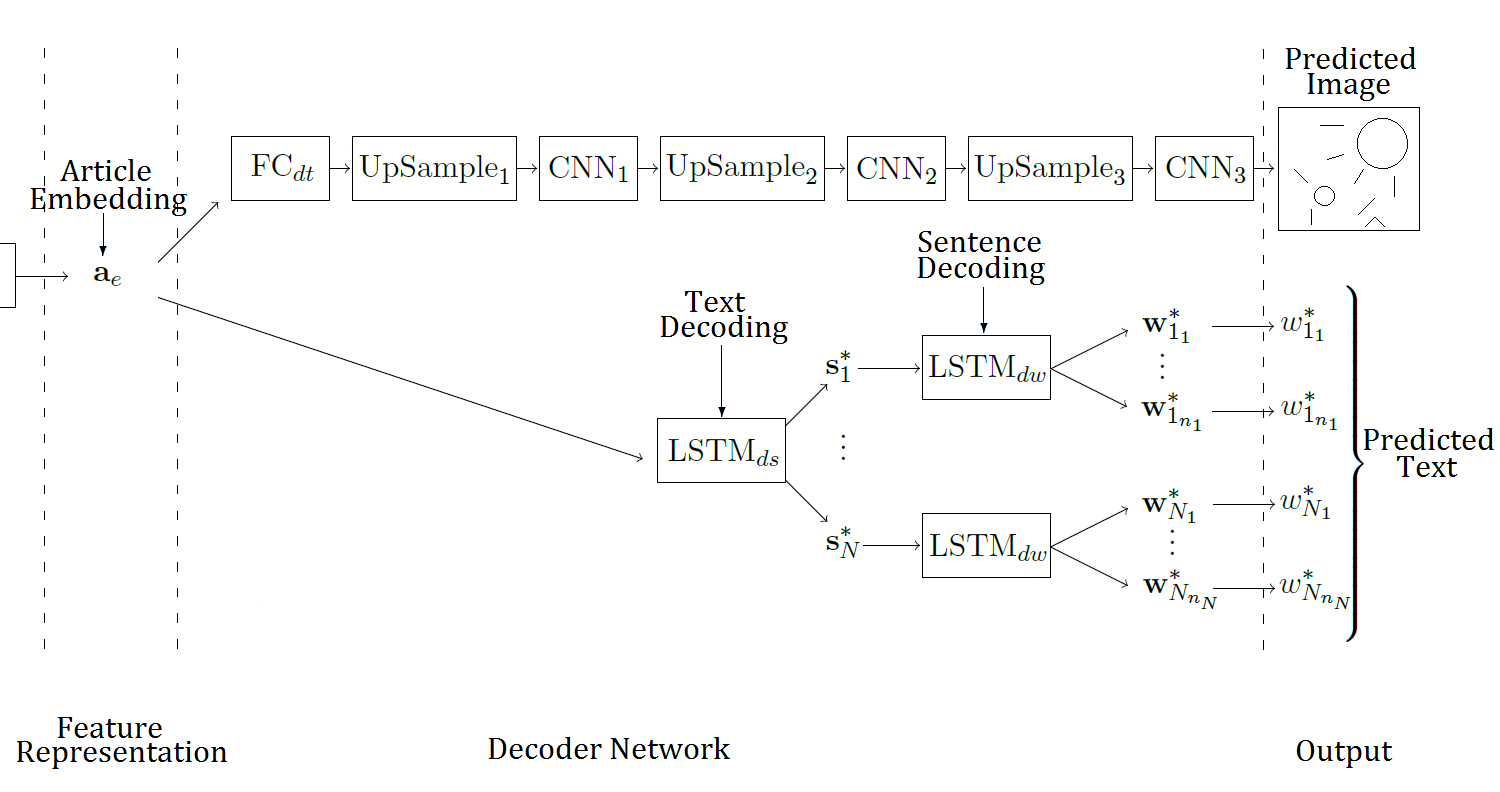 Estimating the information gap between textual and visual representationsChristian Henning and Ralph EwerthInternational Journal of Multimedia Information Retrieval, 2018
Estimating the information gap between textual and visual representationsChristian Henning and Ralph EwerthInternational Journal of Multimedia Information Retrieval, 2018To convey a complex matter, it is often beneficial to leverage two or more modalities. For example, slides are utilized to supplement an oral presentation, or photographs, drawings, figures, etc. are exploited in online news or scientific publications to complement textual information. However, the utilization of different modalities and their interrelations can be quite diverse. Sometimes, the transfer of information or knowledge may even be not eased, for instance, in case of contradictory information. The variety of possible interrelations of textual and graphical information and the question, how they can be described and automatically estimated have not been addressed yet by previous work. In this paper, we present several contributions to close this gap. First, we introduce two measures to describe two different dimensions of cross-modal interrelations: cross-modal mutual information (CMI) and semantic correlation (SC). Second, two novel deep learning systems are suggested to estimate CMI and SC of textual and visual information. The first deep neural network consists of an autoencoder that maps images and texts onto a multimodal embedding space. This representation is then exploited in order to train classifiers for SC and CMI. An advantage of this representation is that only a small set of labeled training examples is required for the supervised learning process. Third, three different and large datasets are combined for autoencoder training to increase the diversity of (unlabeled) image–text pairs such that they properly capture the broad range of possible interrelations. Fourth, experimental results are reported for a challenging dataset. Finally, we discuss several applications for the proposed system and outline areas for future work.
@article{henning:2018:estimating, title = {Estimating the information gap between textual and visual representations}, volume = {7}, issn = {2192-662X}, doi = {10.1007/s13735-017-0142-y}, number = {1}, journal = {International Journal of Multimedia Information Retrieval}, author = {Henning, Christian and Ewerth, Ralph}, year = {2018}, pages = {43--56}, } - Approximating the predictive distribution via adversarially-trained hypernetworksChristian Henning*, Johannes Oswald*, João Sacramento, and 3 more authorsIn NeurIPS Workshop on Bayesian Deep Learning. (Spotlight) , 2018
Being able to model uncertainty is a vital property for any intelligent agent. In an environment in which the domain of input stimuli is fully controlled neglecting uncertainty may work, but this usually does not hold true for any real-world scenario. This highlights the necessity for learning algorithms that robustly detect noisy and out-of-distribution examples. Here we propose a novel approach for uncertainty estimation based on adversarially trained hypernetworks. We define a weight posterior to uniformly allow weight realizations of a neural network that meet a chosen fidelity constraint. This setting gives rise to a posterior predictive distribution that allows inference on unseen data samples. In this work, we train a combination of hypernetwork and main network via the GAN framework by sampling from this posterior predictive distribution. Due to the indirect training of the hypernetwork our method does not suffer from complicated loss formulations over weight configurations. We report empirical results that show that our method is able to capture uncertainty over outputs and exhibits performance that is on par with previous work. Furthermore, the use of hypernetworks allows producing arbitrarily complex, multi-modal weight posteriors.
@inproceedings{henning2018approximating:pred:post, title = {Approximating the predictive distribution via adversarially-trained hypernetworks}, author = {Henning, Christian and von Oswald, Johannes and Sacramento, Jo{\~a}o and Surace, Simone Carlo and Pfister, Jean-Pascal and Grewe, Benjamin F.}, booktitle = {NeurIPS Workshop on Bayesian Deep Learning}, year = {2018}, }
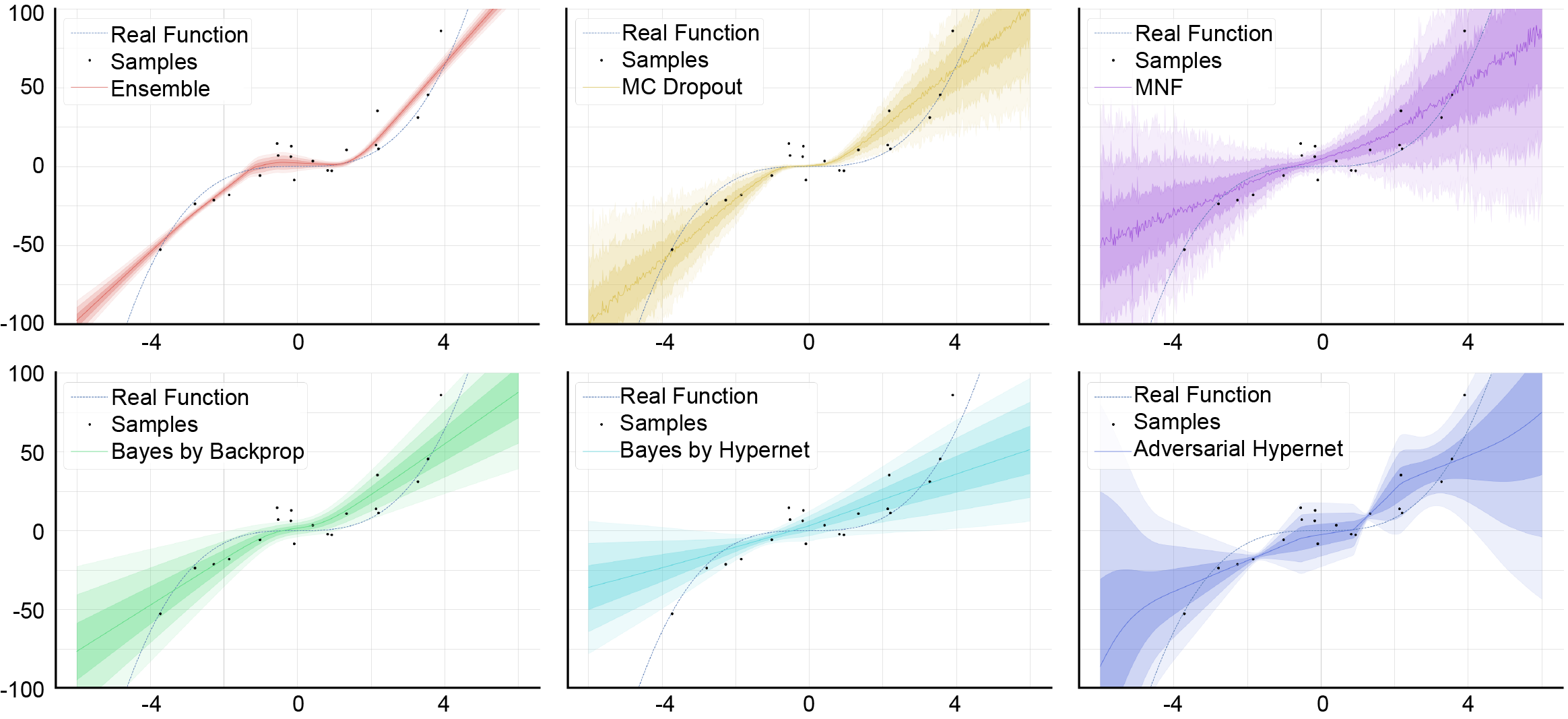
2017
- ICMR 2017
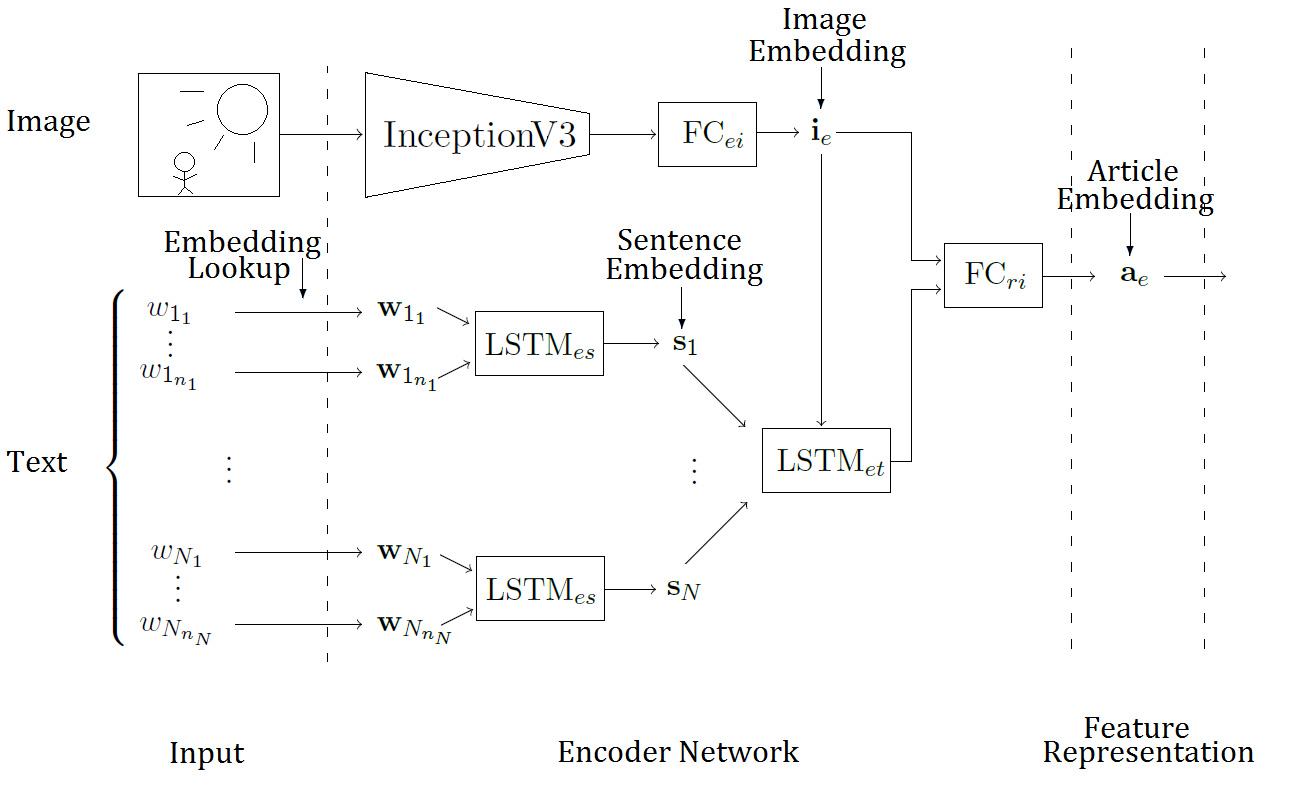 Estimating the Information Gap between Textual and Visual RepresentationsChristian Henning and Ralph EwerthIn Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval, Bucharest, Romania. (Best Multimodal Paper Award) , 2017
Estimating the Information Gap between Textual and Visual RepresentationsChristian Henning and Ralph EwerthIn Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval, Bucharest, Romania. (Best Multimodal Paper Award) , 2017Photos, drawings, figures, etc. supplement textual information in various kinds of media, for example, in web news or scientific publications. In this respect, the intended effect of an image can be quite different, e.g., providing additional information, focusing on certain details of surrounding text, or simply being a general illustration of a topic. As a consequence, the semantic correlation between information of different modalities can vary noticeably, too. Moreover, cross-modal interrelations are often hard to describe in a precise way. The variety of possible interrelations of textual and graphical information and the question, how they can be described and automatically estimated have not been addressed yet by previous work. In this paper, we present several contributions to close this gap. First, we introduce two measures to describe cross-modal interrelations: cross-modal mutual information (CMI) and semantic correlation (SC). Second, a novel approach relying on deep learning is suggested to estimate CMI and SC of textual and visual information. Third, three diverse datasets are leveraged to learn an appropriate deep neural network model for the demanding task. The system has been evaluated on a challenging test set and the experimental results demonstrate the feasibility of the approach.
@inproceedings{henning:2017:estimating, author = {Henning, Christian and Ewerth, Ralph}, title = {Estimating the Information Gap between Textual and Visual Representations}, year = {2017}, isbn = {9781450347013}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, doi = {10.1145/3078971.3078991}, booktitle = {Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval}, pages = {14–22}, numpages = {9}, location = {Bucharest, Romania}, series = {ICMR '17}, } -
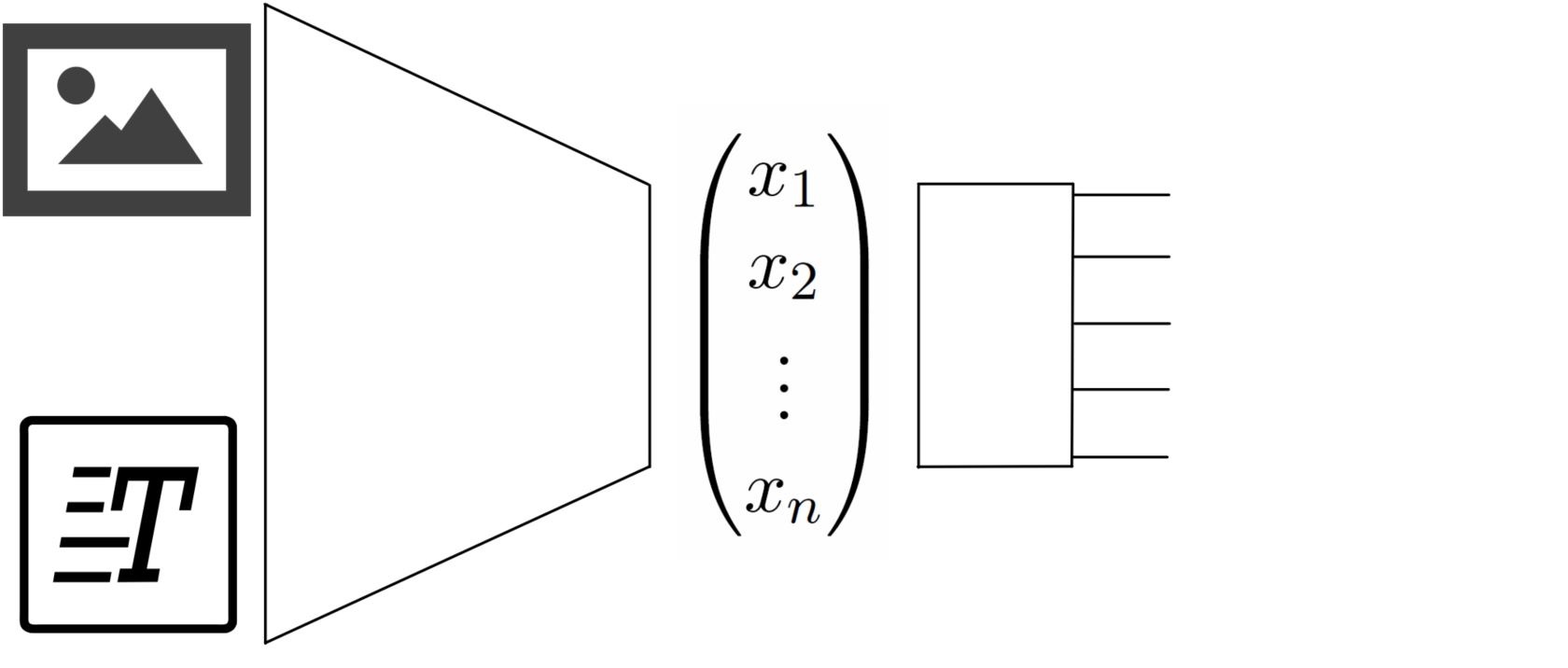 Estimating the Information Gap between Textual and Graphical RepresentationsChristian HenningMaster Thesis , 2017
Estimating the Information Gap between Textual and Graphical RepresentationsChristian HenningMaster Thesis , 2017@article{henning2017masterthesis, title = {Estimating the Information Gap between Textual and Graphical Representations}, author = {Henning, Christian}, year = {2017}, publisher = {Leibniz University Hannover}, }